What is Retrieval Augmented Generation:
Retrieval Augmented Generation can be broken down into 3 different steps. The term Retrieval comes from the idea that the user asks a question, and the chatbot searches and finds the most similar data from the data that you provided it. The Augmentation occurs when the prompt and additional context from the data are used to change the “prompt template.” The generation ultimately occurs when the response is provided back.
When you should use it:
There are three main issues with LLMs in general: : First, there is a lack of domain/internal knowledge that you might have since models are trained on publicly available data. This means that models can’t answer questions about your business or any other more-personalized tasks that you might want to explore.
Second, LLMs often hallucinate. Although LLMs can seem very confident in their response, they can provide incorrect answers to your questions.
Third, the training cut off. In all models, there is a date cut off in data that the model was trained with. This means if you want to ask questions about current information, you won’t get a correct response since the model is unaware of this data.
However, all hope is not lost. As, Retrieval Augmented Generation (RAG) has become one of the frontrunners to solving all of these issues.
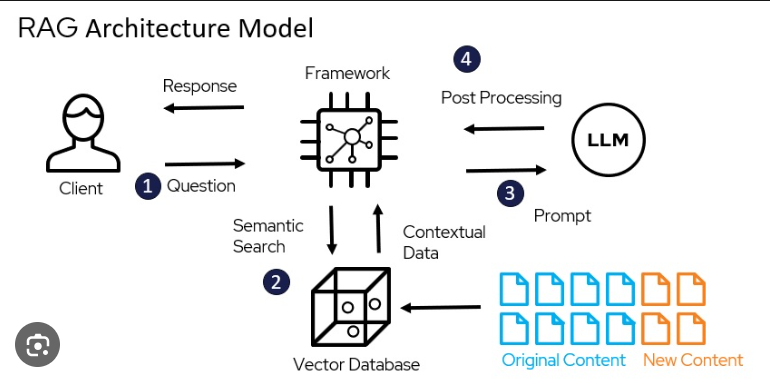
Technical Breakdown
The user can ask a question to the model like they normally would. Then the model searches for semantically similar data points. Usually this means breaking various documents into seperate chunks/tokens that can be then embedded into the vector database. Once it finds semantically similar data to the question, it “augments” the response using the similar data that if found. It ultimately feeds this context/similar data into the prompt that is called to the LLM. The LLM then sends a response back to the user that has been “generated” based on the augmentation of the data.